OK – we now have the full data file for all regions. Firstly a big thank you to Xarthisius who has worked hard to implement the solution, and has singlehandedly kept the scraper working as much as possible. I also want to thank everyone who participated in the effort. Over 500 people helped, and of those people, more than 30 people scraped at least 1000 case numbers.
So – what have we got for that effort? Well I am going to make the data file public so that people can see the data. It is important to understand that we will have to continue to scrape over the coming months in order to capture progress. We will want to see ongoing numbers changes to the data. However, we won’t have to check every number from now on – so there is no need for people to put so much effort in. We don’t have to continue to check case numbers already shown to be holes, and also we don’t have to check certain statuses like refused or issued. Furthermore, we will restrict the checking to only those case numbers that are current. So, if people can just come in and scrape a few numbers each day, that will be enough to capture all we need to see and for the data to remain fresh.
Now – what do we see from this data? Well, this will be a long post because I have to explain some concepts and show how it relates to our data. Some of this is basic understanding – but let’s go over it anyway – just to make sure everyone understands.
The first thing to understand is the draw process. The draw is actually regionalized. Case numbers are assigned in numeric order within each region – all starting at 1. So, there is a case number 2018AF1, and there is also 2018EU1, 2018AS1 and so on. So, we know that based on the country of chargeability, entries are allocated into one of the six regions, and each of these regions has it’s own draw process in effect. I tend to discuss the five large regions (AF, EU, AS, SA and OC). North America (2018NAXXXXX) is so small there are only 9 or 10 case numbers. If you are concerned about NA region – contact me direct.
So – let’s say you are Australian by birth. When you enter, you have the same chance of selection as everyone in the OC region. Some countries get more selectees simply because those countries have more entries – so if country A has twice as many selectees as country B, it means they had twice as many entries. Some countries have MASSIVE numbers of entries, and that is probably due to “agents” publicizing the lottery and either facilitating the entries OR even generating entries programmatically – sometimes without the knowledge of the supposed entrant, but more of that later. The draw system is random and each entry has the same chance as any other entry in the region, so if a single country submits 30% of the entries for the region as a whole, that country will get 30% of the selectees.
OK, having explained that, let’s talk about holes. A hole is when a case number has no selectee. So for example if you check the following cases 2018AF1, 2018AF2 and 2018AF3 you will see that 2018AF2 doesn’t exist. That is a hole.
Holes come from two sources – the first source is cases that are disqualified during the draw process for various reasons such as an improper photo, or duplicate entries. Secondly holes come from countries that are limited during the draw process. Let me explain that second type of hole.
If you look at EU selectees by country as announced by USCIS (on the July 2017 visa bulletin), you can see there are 5 countries that have around 4500 selectees (Uzbekistan, Ukraine, Russia, Turkey and Albania). That number (4500), is also seen in other regions – so it is obvious it is a type of artificial limit placed on the country during the draw process. I have been seeing this same phenomenon for several years – and this results in a stepped reduction in “density”. Density is the number of real cases per N number of case numbers. So – let’s imagine we took cases from 2018AF1 to 2018AF100. If there were 40 holes we would have a density of 60% in that range of 100 case numbers. Why does that happen? I can explain it this way:
For simplicity let’s ignore derivatives for a moment.
Let’s imagine a region that has only 3 countries, and instead of 4500 being the limit, let’s assume the limit is 5000.
Country A has 100k entries. Country B has 1 million entries. and Country C has 4 million entries.
The chance of being selected in that region is 1%. The numbers are picked at random, so the countries would get the following distribution. Each time country A gets a selectee, country B would have 10, and country C would get 40.
So country A would get 1000 selectees and those selectees would be spread out across the whole case number range of case numbers.
Country B should get 10,000 selectees, but because of the limit, they only get 5000. However, ALL their 5000 at in the first half of the number range.
Country C should get 40,000 selectees, but because of the limut, they only get 5000. However, ALL their 5000 would be in the first 12.5% of the total case number range.
If the case numbers went up to 50000 (which takes into account some number of disqualification holes), we would see density reduction at 6250 (country C), then at 25,000 (country B).
So – as you can see the density is very important. Why? Well in the last VB, the max case number made current went from 8200 to 10700. Looking at the data, that 2500 number increase included 1991 real cases. The rest of the numbers were holes. So – because the density decreases after 10700, to get the same number of cases (1991) would now require an increase to 2018EU14333 – that is 3633 case numbers. Now – in reality, the way the VB progress is determined is more complicated that that simple formula – but it makes the point clear. As density decreases, VB progress can increase. And, three regions (AF, AS and EU have density decreases because of draw limited countries.
By the way – this 4500 number and the concept of limiting countries duringb the draw is only loosely related to a rule you may have heard of that no single country can receive more than 7% of available visas (globally). That rule is correct and real, BUT limiting a country to 4500 selectees is NOT how that 7% rule is enforced.
OK – so now I am going to show the density charts for each region and highlight on the charts when there are country limited density drops. The following charts all express density as the number of cases per 100 case numbers.
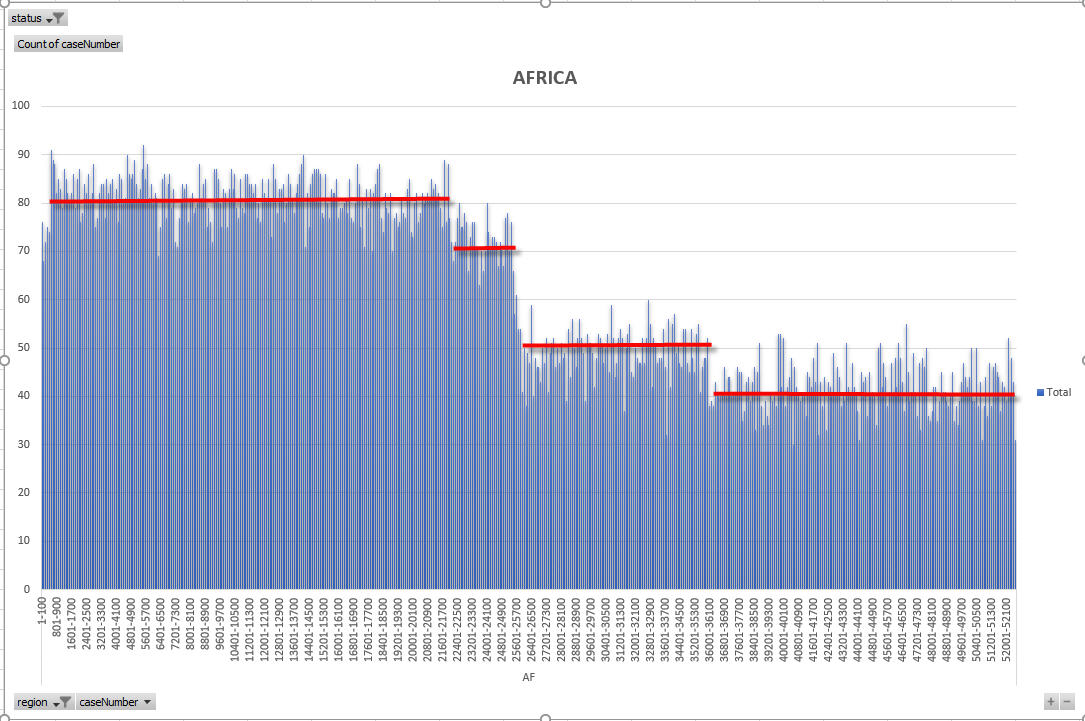
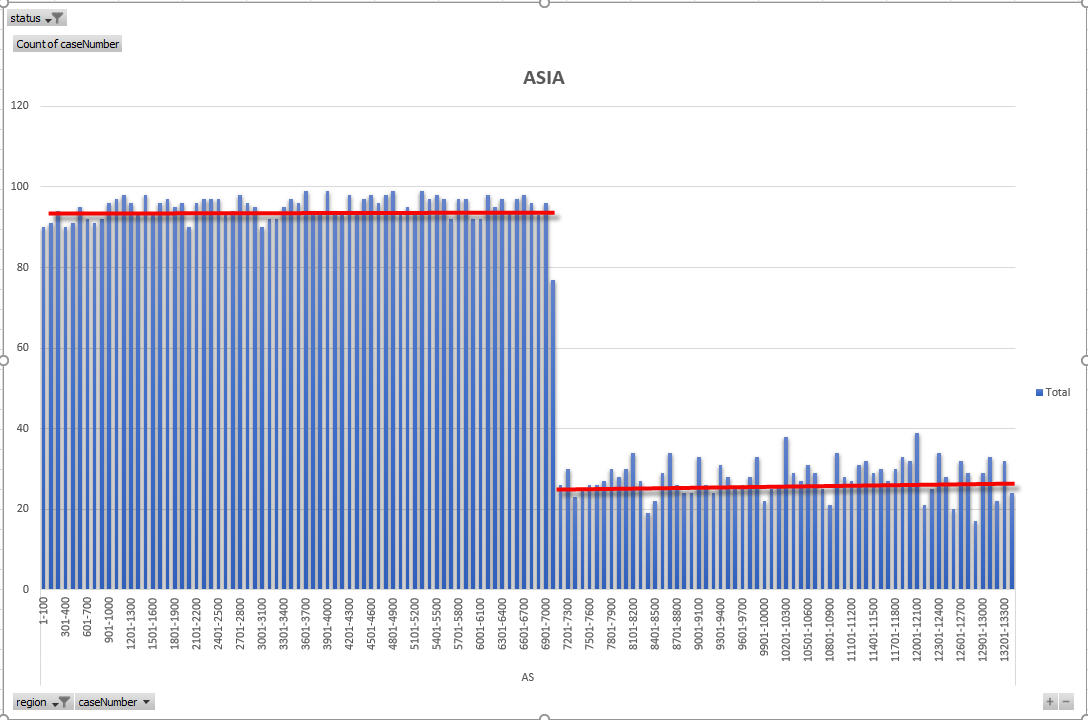
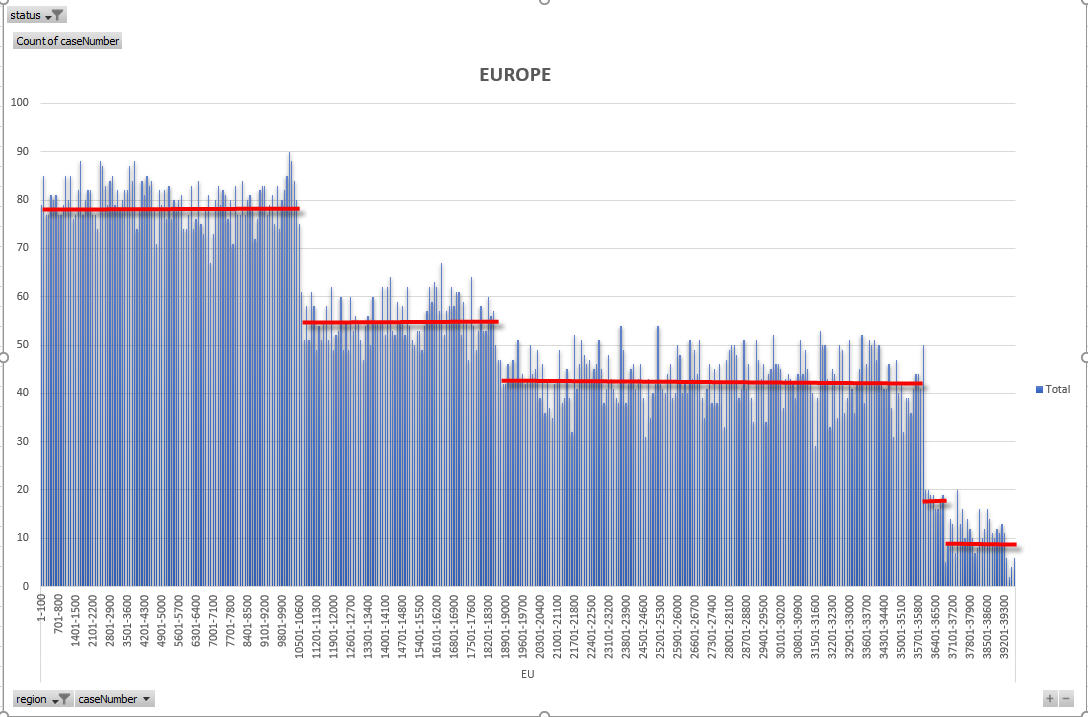
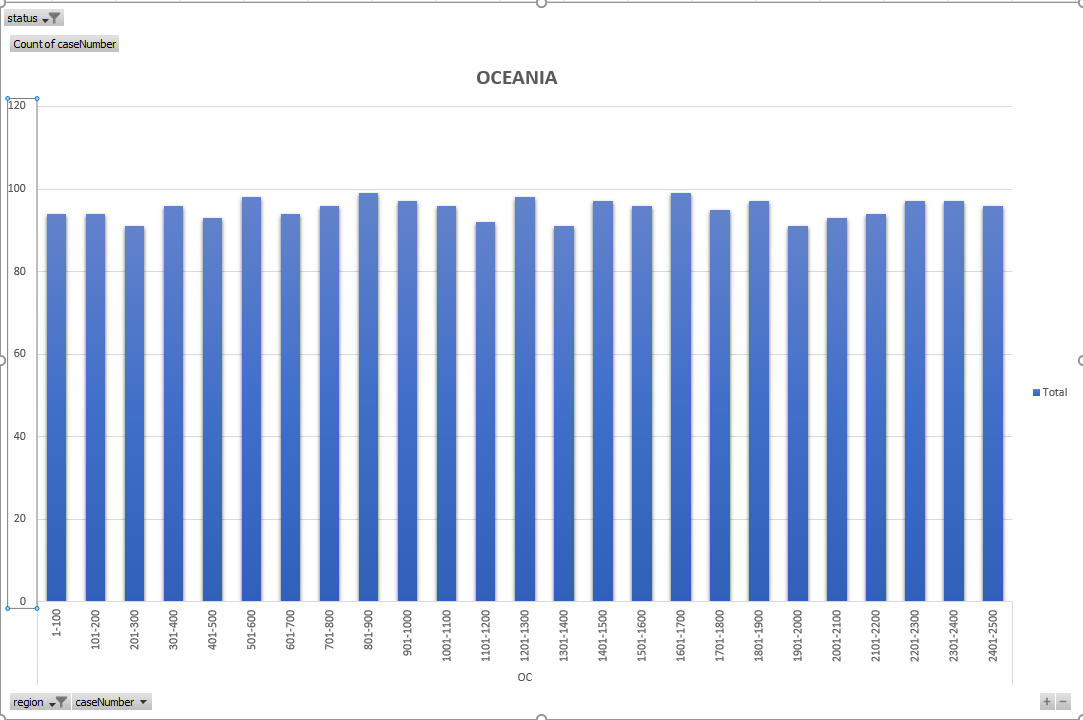

So – from the above charts and explanation you should be able to understand that because density decreases for the three large regions, those regions can see an acceleration of VB progress in later months of the DV year. I cannot pick exactly which countries cause which density drops in all regions, other than the very clear drop in Asia region which pinpoints the limitation of Nepal and Iran (at about 2018AS7100).
By the way, the file also gives us the maximum case numbers we have found in each region. Those case numbers are:
AF – 52581
EU – 39695
AS – 13396
OC – 2500
SA – 2457
There is a chance that there might be a few cases above our max case numbers. The scraper was programmed to assume the cutoff had been reached once it had found nothing but holes for over 100 numbers. So – if you have a case number higher than this data suggests, let me know.
Xarthisius has created a tool to present all this data in a very useful format. You can download the data in csv format, get nice graphs showing the counts of all the status types for each region, and each country. It really is a nice tool!
https://dvcharts.xarthisius.xyz/ceacFY18.html
As far as VB progress goes, as I have already detailed there is going to be a slightly increased acceleration over the numbers I had suggested in my VB progress explained post. That post was written (in early October) with a focus on EU region. Rather than the 2500 increase I saw for the March interviews, I think we will instead see something around 3500 increase (to about 14000/14400). Once the next density decrease is hit, progress can move faster still in later months. However, please read my earlier post to get a reminder about VB progress NOT being the perfect predictor for final cutoffs. That will take more analysis, and must consider response rate, issued rate, derivative growth rate and so on. EU is easier to predict because none of the countries are being restricted during the VB as they are in AF and AS region. AF and AS are NOT so easy to predict.
AF sees a number of density decreases which will each help accelerate VB progress BUT the restricted countries (Egypt and Ethiopia) make the calculation more difficult. Over the coming days we will see the next VB, and I will try and come up with predictions after that – at least in broad terms. I would like to hear from Egyptians to determine the max Egypt case numbers assigned. Egypt enjoys a high success rate and a high number of selectees, so it is possible that not all Egyptian cases will be interviewed, BUT I don’t know the max case number for Egypt so I have no way to guess where the cutoff might come.
For Asia, the travel ban is a BIG influence, BUT we really don’t know how KCC will handle the ban from this point forward NOR do we know whether the ban will stay in place. So – whilst we know that Nepal runs out of selectees by 7100, we can expect slow progress until that point. It is somewhat surprising that Nepal has so many selectees concentrated in the first 7100. That does make me think we will see a limit hit for Nepal at a lower than 7000. This is because of the 7% limit I mentioned earlier in the article. Like Egypt, Nepal enjoys a high success rate and a high number of selectees – so Nepalese cases above 6500 must be considered somewhat at risk.
So – it still remains a case of wait and see for a lot of people. I will spend some time on alaysis of the data in the coming days and will publish any findings. I hope this article has explained some things for you.
If you want more detail about the concepts discussed here, you can read these posts

January 5, 2018 at 06:26
Thank you
January 5, 2018 at 06:30
Please Simon try to expect Kam will get Egypt in the next publication in March
January 5, 2018 at 06:30
great work Mr. Simon, thank you for all !
God bless
January 5, 2018 at 07:02
Thank you for the explanations. After you have seen these data’s is there an update on your safe limit predictions on EU case numbers I think before you mentioned 37K. Do you think for AOSers EU38K has any luck?
January 5, 2018 at 14:29
I need more time to work on that.
January 5, 2018 at 15:11
the same concerns here!
January 6, 2018 at 14:18
Same here 🙂
January 5, 2018 at 07:12
Great work and analysis. Thank you for all the effort.
January 5, 2018 at 07:13
hi brit…which lot contains case AS3580?
January 5, 2018 at 14:29
Huh?
January 5, 2018 at 07:20
Thank you, Simon!
Looking forward for the next article
January 5, 2018 at 07:51
Do you still think that OC 24XX has no luck after this exercise? Thanks for all your hard work Simon
January 5, 2018 at 14:31
That assumption is confirmed by this data (although it was already obvious).
January 5, 2018 at 07:51
That’s some excellent and thoroughly presented data, thank you Simon, and Xarthesius, for those that WILLING TO READ, and spend some amount of time studying, obviously will have their doubt answered, have some question though Simon:
1. I look into Jakarta embassy, for CN 4000++ still has no data, I assume because CN is not current yet?
2. Sorry for bit oot question, what program that Xarthesius made those data? Virtual basic? Just curious though
Thanks
Nis
January 5, 2018 at 14:33
1. Yes, with so few selectees, that isn’t a surprise.
2. I’ll leave that to him to explain.
January 6, 2018 at 08:26
Indeed, never pass 200, according to your analysis, those very few selectee due to very few application submitted?
January 6, 2018 at 15:48
Exactly.
January 5, 2018 at 14:34
2) Scraper and analysis tools I use are written in Python. Visualization on my website uses Chart.js
January 5, 2018 at 15:30
Since I am a Python noobie, maybe even I could understand the code!
January 6, 2018 at 08:23
I only knew phyton as snake though, lol
January 5, 2018 at 17:41
Hi nis..do you from indonesia
January 6, 2018 at 02:43
Hi Nis….do you from indonesia ?
January 6, 2018 at 08:24
Hi Qiu Qiu, yes I am
January 6, 2018 at 10:22
Hoyaaa….me too Nis Daniel.
January 6, 2018 at 16:04
Nice to meet fellow indonesian here
January 5, 2018 at 08:08
Thank you Brit for the wonderful job you’ve done. I would like also to thank everyone that worked on the CATCHAS.
Obviously the density or the derivative rate is bigger than expected for EU region (you expected the max CN to be about 45XXX for EU). Do you think that the safe number should be lower than EU37xxx?
January 5, 2018 at 14:36
I need some time to work on that. Yes, density changed because there were 3 countries that has very different entry counts. So yes – I need to look at the data.
January 5, 2018 at 08:29
Thanks a lot for you Brit and Xarthesius and for all other persons that contribute to solve capthca.
January 5, 2018 at 08:50
This is very interesting, good job!
Thank you Simon, Xarthisius and all the people who helped.
Just one thing; as you told me before and depending on the embassies, some people might be missing on these figures such as the derivates added after the entry like new husbands, new wives and recent born babies, right?
January 5, 2018 at 14:37
Yes – that is the derivative growth rate I mention at the bottom of the article. PLus – this whole article was about case numbers. I am yet to discuss derivative rate for DV2018.
January 5, 2018 at 09:03
Hello Brit
I am from Liberia, and my case number is AF000442xx. Do I stand a better chance of being called for interview?
January 5, 2018 at 14:38
I need time to look at the data. Patience.
January 5, 2018 at 09:23
hello, its alibaba (over 1200 captchas solved 😉 ) So I checked the file with the data scraped and the status for my number is “none”. But when I go to nvc check it says that my number is “at nvc”. Obviously im less worried seeing the status at nvc, but still cant get why the status is “none” im the data we scraped. many thanks for your kind assumption 😉
January 5, 2018 at 09:35
Simon, please disregard this question. I can see my status as at NVC after all. Once again many thanks
January 5, 2018 at 14:39
Ahhhh – I answered the other one first. No need to email me!
January 5, 2018 at 14:38
email you precise case number to me at britsimon3 at gmail.
January 5, 2018 at 09:31
Thanks for the effort.
January 5, 2018 at 09:47
Hi Brit. For EU: 1-10600 – for this range quantity of real case numbers is~ 80%. November cut-off is 4500. 4500*0.8= 3600- real cases. 2700 visas were issued for this period. Derivative rate is 2 (aprx.) It means only 1350 cn got visas. 3600- 1350= 2250 cn did not get their visas. where are they???
January 5, 2018 at 11:35
Hello, have you also considered non response or just holes?
January 5, 2018 at 12:18
Probably Brit has good sleep right now. I’m not trying to answer your question, but looking at it i also have one. What is important now is derivative rate. Behind every responding cn are people, not one but group of family members. Trying to find average derivative rate. Seems that for 3 months is 2,22 Not sure is it ok, probably Brit will know better and will correct me. 10700 is cut off for december. Substracting holes and non responses actual ratio seems to be 40-45% so actually around 4815 cn that responded a were interviewed. From 3 months we have 10374 selectees (issued, ready (not sure this value as i don’t know if in this group are also people with cn higher than december cut-off), refusal, in transit. So those selectees who responded 10374 divided by count 4815 of cn gives me rate 2,22 per cn. Thats very rough estimation especially as i’m not sure about count of ready cases- are those only till dec, or january/feb also. I’m not trying to answer – that’s host privilage, but reading this i also have my concerns and questions. Brit for sure will know and will answer and correct me ?. Thank you and regards.
January 5, 2018 at 12:39
We have a facebook group for SA winners and we are doing a statistics and the derivatives range for us is 2.47. Also if you look in the visa bulletin web Page you will find statistics from october and november
January 5, 2018 at 13:14
I forgot to mension those numbers are for eu.
January 5, 2018 at 14:35
what is your facebook group called so i can look it up
January 5, 2018 at 15:56
Venezuela greencard
January 5, 2018 at 15:17
In SA there are 4995 announced selectees on 2301 cases – meaning a starting derivative rate of 2.17. That rate grows through births and marriages.
January 5, 2018 at 13:28
Totaly wrong. I took cutoff for february not dec, but still not sure about this if ready staus is also for Jan/feb.
January 5, 2018 at 15:08
You are correct about this. Density is just the start of what we need to know and the response rate, derivative rate (plus growth) and the success rate are all important. I need some time to do some analysis and write that up.
January 5, 2018 at 14:48
Not all cases respond, not all cases get approved. More detail coming in another analysis post.
January 5, 2018 at 09:58
OH SIMON after this draw as density is high in af till 22000 and high select number from egypt and ethiobia restricted countries then VB will come with the same rate or down 2000 each month and more than 20000 for egypt not safe
January 5, 2018 at 14:50
Don’t jump to conclusions.
January 5, 2018 at 11:05
Hi. I have a quick question. Do you have 100% confidence in the maximum number for the EU? I mean, are you absolutely sure that some numbers (for example below 30xxx) will be invited for interwiev? I’m asking because my cn is 338xx and if I want to move to the USA, I have to make irreversible decisions. In your last predictions, you said the numbers below 37xxx are saved, how does it look after ceac data? Thank you
January 5, 2018 at 14:54
You should not count on ANYTHING prior to having the visa in you hand.
As for my opinion – wait for further analysis.
January 5, 2018 at 11:35
Dear Britt
So it means cases above 6500 for Nepal have low chance of getting interview.
January 5, 2018 at 14:58
I said – “have risk”.
January 7, 2018 at 11:04
Thank u Britt
What do you my case no 6550 would manage to get 2l and call for interview?
Your view pls
January 7, 2018 at 16:36
Read my latest articles, and remember to give your region when you quote your number.
January 8, 2018 at 12:12
Oh sorry Britt
It’s As6550.
And below what case number would you consider as safe from Nepal.
Thanks
January 8, 2018 at 14:48
I have written that the risk range is somewhere between 6500 and 7000
January 5, 2018 at 11:59
South America from what i c seems to be in a bit of stable range not too much drop in density…but i am still wondering the approximately safe zone happens to be around 1500 case number …
January 5, 2018 at 15:01
The current pace for SA (and OC) will continue. So – SA is at 625 after 5 months – you can add 7 months at 125 for an APPROXIMATE idea for SA.
January 5, 2018 at 12:07
hi simon,
according to article there is a chance that my number never comes EU330xx
January 5, 2018 at 15:01
Where does the article say that?
January 5, 2018 at 12:07
Hi Brit, thanks to you, xarthisius and all the people who resolve captchas.
Q1.- I did not understaind the grafics for caracas, we are 2457 case numbers in SA region, and the paces in the grafic is each 1000
Q2.- wich is the differences between case numbers and number of cases?.
Q3.- why the density in SA keep almost the same all year?
Q4.- With the high no response cases in SA it is a probability for been current or the safe number could change?
Thanks again Brit, and just let me know when you need to solve more captchas 😀
January 5, 2018 at 14:56
Re Q1: I just put a note explaining that above the “embassy” chart. In short a single embassy can process people from all six regions (it’s just a matter where those people reside at the moment). That’s why the axis needs to cover the largest, global number (basically number from AF). In order for the chart to be legible I had to choose an arbitrary step (1000).
January 5, 2018 at 15:28
Ahhh – he was talking about your charts. Thanks mate!
January 5, 2018 at 15:04
1. The groups are 100.
2. Not every case number has a case – because of holes. Is that what you are asking?
3. There are no countries that are limited during the draw – so the only source of holes in SA (and OC) are the pre announcement disqualifications. Those are randomly distributed throughout the case numbers because the draw is random.
4. Current, no. Remember, response rate increases over time. However, trying to predict the final number this far out is tricky.
January 5, 2018 at 12:29
Hmm—It is getting hotter in the DV lottery pot!!! Thanks a lot Sir. It’s amazing the way u go about this DV lottery stuff u know. God bless u as we wait for more understanding of our different DV lottery standings
January 5, 2018 at 12:47
I want to make an approach, please correct me if wrong.
For EU,
In the first three months, 3296 issued and 618 AP, let’s say AP’s are issued: 3296+618=3914 visas are issued.
Let’s also say that derivative rate is equally distributed between all cases.
I want to make an AREA approach:
If there is five density groups: 10500, 7800, 17500, 1400, 2100
Let’s calculate the areas under the line:
10500 * 78% = 8190 cases
7800 * 55% = 4290 cases
17500 * 43% = 7525 cases
1400 * 18% = 2520 cases
2100 * 9% = 189 cases
———————
22714 cases
Let’s say 6000 * 78% = 4680 cases are processed in the first 3 months.
If 3914 visas are issued for 4680 cases.
For all cases, there must be 3914 * 22714 / 4680 = 18996 visas must be given in order to give all that cases that wants visa. If 18996 visas are going to be allocated for Europe, then the region may go current.
January 5, 2018 at 13:45
Buro, have you also looked at Xarthisius graphs? Really high number of non response. Seems that only 45% of cn from 0-6000 range were interviewed. This is also important and we cannot be sure how will this go later. What derivative rate you took for your analysis? Pity there is no „ delete post” option – i would delete all my posts above before Brit can read it ?
January 5, 2018 at 15:23
Too late – I read them. And I think we are both more confused! 🙂
Give me some time to look at the data…
January 5, 2018 at 15:33
Sorry for wreaking havoc?
January 5, 2018 at 17:00
Haha!
January 5, 2018 at 14:09
And one more thing, eu or af region? Because numbers are for Africa. Eu has 3923+410=4333. And those are rather out of 2700 cases 6000*0,45=2700. So roughly we can say 4333 visas (ap included) per 2700 cases in 0-6000 cn range.
January 5, 2018 at 14:45
Oh sorry, I realized that i took Africa. *seeking for delete post* 😀
Then 4333 * 22714 / 4680 = 21029 visas must be available
BTW, the derivative rate is considered equal between all cases
January 5, 2018 at 15:20
That is too simplistic. You can’t assume the rate from the first two months will continue for the whole year.
Wait for my analysis to explain more.
January 5, 2018 at 13:37
the Security numbers remain stable or you think there is a change for the afrqiue ???
January 5, 2018 at 15:21
I am still working on the data.
January 5, 2018 at 15:54
Hi brit. I have 23xx in SA. I have a chance to interview? And if your answer is yes. To When? Thanks
January 5, 2018 at 17:01
Probably no – but wait and see.
January 5, 2018 at 16:29
Hi Brit
Hopefully first mission is completed by the help of the community.
Now it turns to second one I think.
From now on, should we scrape captchas every month, for further readings on the data’s?
January 5, 2018 at 17:02
Yes – we should continue to scrape ongoing, so we can keep the data fresh.
January 5, 2018 at 23:20
Xarthisius – your CN will be probably ready for march – I hope after succesfull interview you will still stay with us and provide your knowledge and help at scrapping 🙂 Great job and thanks for Brit and you for everything we could make here 🙂
January 5, 2018 at 16:45
Agreed. For Europe 3 cutoffs, 10584 for Uzbekistan, 18808 for Ukraine and 35974 for Russia. For Africa 3 cutoffs, 22019, 25487 and 36010. For Asia just one cutoff, 7098, possibly the same for Iran and Nepal
January 5, 2018 at 20:32
where did you get these numbers?
January 31, 2018 at 14:03
The first cutoff for Africa is 21467-22073, possibly Ghana again
The second cutoff for Africa is 25206-25994, possibly Egypt again
The third cutoff for Africa is 34658-37147, possibly Democratic Republic of Congo.
January 5, 2018 at 17:28
So. SA until now will keep 1500 for safe numbers?
If is that correct SA will have only 840 visas? I read in a early coment that for SA you can calculate 125 case numbers for the next 7 month. If we assume that we also can assume 70 visas issued for each month. So 70×12 is 840 total visas. If is that correct why 2017 was 1800 total visas and 2016 was 1500 total visas and now will drop to 840 total visas.
Thanks Brit
January 5, 2018 at 17:55
No that is not correct. Stop thinking that way.
Take the first 1500 case numbers. There are 1409 cases. STARTING derivative rate was 2.17 (4995 selectees spread over 2301 cases). So – from the 1409 cases, there are 3057 people. Then we have to consider derivative growth rate, response rate, success rate and so on. You cannot apply simplistic approaches, and you should understand that it is very difficult to predict final outcomes this far out.
January 5, 2018 at 20:36
Hi Simon!!
Another factor to consider for SA region is that the embassy in Cuba has sent immigration visas to the Colombian embassy. For some selected, it will be very difficult to attend.
It may increases opportunities for those selected with high CN. Right?
BR/
January 5, 2018 at 20:54
HI day where are you from?
Where did you read that? I was looking in the october and november statistics and no visa in colombia and cuba was issued
January 5, 2018 at 21:32
It has always been difficult for people in Cuba – but I think those people will find a way.
January 5, 2018 at 18:01
Hello Brit,
my case number is EU181XX.
Do you think it’s in a safe range?
January 5, 2018 at 18:18
Really – I don’t think you even need to ask that.
January 5, 2018 at 18:14
Hello Britsimon
my case number is AS00011700. Do I stand a better chance of being called for interview?
January 5, 2018 at 18:19
Wait and see is all I can say at the moment.
January 5, 2018 at 18:25
Hi simon
What about 23000 from Egypt do you think still safe
January 5, 2018 at 18:44
I don’t know.
January 5, 2018 at 18:47
I ask you last month the same question and your answer ( yes safe )
January 5, 2018 at 19:01
So now I am seeing the data I am less certain. If you want 100% certainty, wait for the VB.
January 5, 2018 at 18:58
Dear.Simon in your opinion and with u experience when we can determine safe number is safe or not espicially in Egypt
January 5, 2018 at 19:01
I don’t know.
January 5, 2018 at 18:46
I have seen some cases from Egypt 24000 ، 26000 ، 29000 ، 30000، 39000
January 5, 2018 at 18:59
That’s interesting – but unlikely.
January 5, 2018 at 18:47
Hi Brit,I’m from Liberia my case number is 2018Afxxxxx156 is this number now current?
January 5, 2018 at 19:00
Yes
January 5, 2018 at 20:11
After receiving and reviewing the CEAC data, you mentioned the vb prediction for EU 3500 for march interviews, could you shed some more light please, cn EU 178** would end up in april interview?
Thanks Sir
January 5, 2018 at 21:29
That obviously depends on how far we get in march – so wait to see.
January 5, 2018 at 20:54
Hi Brit,
Will my number AF16XXX be current in march release?
January 5, 2018 at 21:10
In March??? WTHF, To see the VB for march needed only some days and you guys have time to prepare the necessary documents for the interview. The problem here is for high CN, on all regions. For that Brit need time to study the data and give us an explain.
January 5, 2018 at 21:35
Thanks.
January 5, 2018 at 21:34
The VB will be published in a few days time….
January 5, 2018 at 21:55
What abouth EU356** ???
January 5, 2018 at 22:08
Guys, guys let’s get a little bit serious here! I don’t know Brits at all but I believe he’s not a robot (unless he proves me wrong) and can also get feed up with some things. I remember calling myself a ‘silent observer’. But I’ll let you guys know one thing; I don’t ask questions not because I don’t have any. It’s simply because I have read all of Brits’ posts. And at any moment I come online, I’ll first read any new post, all the comments/questions posed and responses from Brits. In fact, with the posts I get responses to all my worries in advance. I get very worried for Brits when I see people repeating similar questions and especially people asking if their numbers are safe… and even when Brits says ‘wait and see’, we still go ahead to insist on the question or ask it in other words….come on guys! Let’s even use some common sense, not be lazy in reading and give time for Brits to analyze data for us and equally spend some time with his family. Brits, sorry for my long post but I guess it’s worth it; some of us need to grow up and get responsible; let’s behave like potential Americans.
Brits, I greatly admire your patience… very few of your type exist out there. Kudos! I pray I could possess just half of this virtue of yours. God bless you and your family.
January 5, 2018 at 22:12
🙂
January 5, 2018 at 23:43
Totaly agree. This guy has job, family and his own private time. Don’t ask simple questions: is my number safe or when will i have my interview. Brit even with his big process and analitical knowlegde can’t predict everything. Let’s respect his time and do some work by ourselves. Good ones, wrong ones with errors but try to do your own judgement. Don’t flood him with questions you can answer by yourselves or questions no one can answer with 100% certainty. there are many factors we still don’t know and don’t expect answer other than wait and see. I don’t understand people asking will my interview take place next month even their CN number is few hundreds above last cuttoff with VB progress over 2000 previous month – use your imagination. Use your skills and imagination – everyone of us got wonderful tools thanks to Brit and Xarth – look at them and use them. It’s like now we know everything – we know some very useful part, but still only part. Rest is hard to predict – let’s give Brit some time, for sure he will share his thoughts with us, but don’t flood him with questions just because we got only part of the needed data. Large part, but still part – rest still needs to be estimated – that needs time. Let’s wait for next VB – only few days, this will also help to see if VB changes for some regions that we expect to change. Wish you all patience… 🙂
January 5, 2018 at 23:45
“It’s like now we know everything” – should be “It’s NOT like now we know everything”
January 5, 2018 at 22:47
Hi Brit I just look at the data, it is really cool. I m impressed?. So I check my country, between 9001-10000. It shows 4 issued, 1 refused, 8 no response and 0 Ap. I believe is 2018 graphic.So here is my questions
1) what does no response means in this case.
2) what does it means for those who have not get their 2nl yet.
Thanks
January 5, 2018 at 23:34
1. While the case is at NVC, and that case is already current (so should be scheduled) we consider than a no response – meaning the selectee hasn’t submitted their DS260. Of course they may still submit it, so we will continue to check. Also – cases not yet current are shown at NVC too – we will only know which have responded once we see those that have been scheduled.
2. I think my answer explains that.
January 6, 2018 at 03:51
Judging by the numbers you provided and the fact that you are talking about specific country, you were looking at the CEAC Data for Embassies chart. “No response” label was my mistake (copy&paste error). It should have read “Ready”. It’s now fixed.
January 6, 2018 at 01:52
So in other word if the case is currently which it is in this case and said at nvc. The case has been already processed and just waiting to be scheduled. Am I correct?
January 6, 2018 at 01:59
No. The case might have been processed, or might not.
January 6, 2018 at 06:57
Hi Brits. Still on no response ;when looking at the data per continent (e.g. Africa ) It seems the non response rate is pretty high even for certain low case ranges ( e.g 17000-18000). If indeed that’s the case ,and people haven’t actually submitted their D260,what could be the impact on high case numbers . To be honest my case is pretty high at AF49XXX from Cameroon. At this point I’m hoping for a miracle ?
January 6, 2018 at 15:52
I’m about to publish an article with some explanation. Just let me say this. The response rate starts low, and although it increases over the year, it is a large factor, and the reason they select more people than there are places. However, you will have a long nervous wait – I cannot give you some bold and confident answer at AF49XXX – but neither would that be considered a miracle if you got current – you are in a risky range, not a “GIVE UP” range.
January 7, 2018 at 16:22
Hey gee22stong I’m also from Cameroon and my CN is pretty higher than urs let’s just wait and see
U can drop a message through 678034254 so that we can get in touch
January 6, 2018 at 10:27
Goodmorning dear Brits and all the members out here.
i have been around for quiet a long time now and so i know soo much about happenings here.
As such i would like to make some suggestions.
1. Brits is a wonderful man who is one of a kind. since i discovered this site i have been very much enlightened about this dv process to the extent where my knowledge is now more than an immigration layer friend of mine based in Georgia USA,. infact in terms of dv lottery, i know more than he knows.
This is just because i read everything Brits posts here, be it a new post or an answer to a question. i have linked all my emails to this site and i recieve every new post by Brits by email and read without even logging in to the site.
so if you will observe, i hardly asks questions because am always here reading.
BUT THE ISSUE IS THAT,
A lot of the people who ask simple, unintelligent or CLASS ONE questions on this site are in these categories:
1. people who are new to this site who dont even know how things are like over here
and who sometimes speaks, read and write little or no English at all.
so they might read everything here but would in a way or the other want Brits to hammer their specific need for them simply for them to try to understand either by themselves or by interpretation by a third party.
2. PEOPLE WHO JUST DONT WANT TO READ: these are the real disturbers who sometimes gets me more angry than any other person. Brits can write a long post and just after that you can see someone asking a question addressed in the very first or second line. it means the person just dont want to read which is a very irresponsible way of living as a human being.
3. people who read but in a way or the other still want to communicate with Brits because they simply admire him for what he does for the community.
4. people who are seeing the site for the very first time who dont even know that billions of issues have been addressed here by Brits
These are my suggestions to the members other than Brits going foward:
1.when someone asks a question which is unintelligent, please do not scorn the fellow but just answer if you are sure of the accuracy in order not to mislead.
But if you dnt know the answer but you know the link on this site where it has been addressed by Brits, just copy the link and post it here for the fellow to open and read or better still leave it for Brits himself to deal with it his own way.
Brits have answered plenty questions by simply posting links and it really helps.
but if any other person apart from brits just begins to scorn someone for asking an unintelligent question, how do you know if the person is new to the site or not?.
The person might just leave the site, carrying a wrong impression about the site mean while we all know how educative this site is.
Over 500 members solved captchas but how many of those even asks questions ?. it means we those who simply read are many than those who dont read
The MAYOR of this community has two very important qualities which i think we should emulate.
PATIENCE AND TOLERANCE
I encourage you all to make Brits work easier by just READING and learning to respect his time and efforts so we dont bother him with unintelligent questions.
PLEASE DONT SCORN IF YOU ARE NOT BRITSIMON
thank you all and long live Brits!!
January 6, 2018 at 15:45
I am Britsimon – and I am not going to scorn your comments and suggestions. Thanks!
January 6, 2018 at 10:29
According to holes and not response I think the AF will go current at the end except Egypt and Ethiopia
January 6, 2018 at 15:44
I am working on an article now.
January 6, 2018 at 12:27
Hello Brit. I am very worried. On monday i have medical appoitment but my period came. Does this effect my medical appointment analysyes and interview? What should i do?
Ps. Sorry for the question but i have no one else to help me.
January 6, 2018 at 14:33
No affect on your medical.
January 6, 2018 at 16:05
thanx a lot Brit.
January 6, 2018 at 13:23
My case number 2018AF00042*** When do I expect an email for an interview
January 6, 2018 at 15:42
A long wait. Long enough to read some of my articles.
January 6, 2018 at 15:26
Dear Sir,
Thank you for helping us always
1. my sponserer is an aunty. she is a pensioneer.she has an AMERICAN passport. for my visa interview she gave me copies of her passport,2015 W2 form, 1099 form and tax return form.along with an affidavit.She has lost her original documents of the above mentioned forms except the pass port.& the affidavit.For my visa will the photo copies are sufficient?
2. My sponserer is not showing any deposits behalf of us.so that we are showing our assets. I mentioned them below .savings account 22000 USD ,our car and two plots of lands and three houses.they are worth more than 95000 USD.also we have a very good monthly income.I wanted to know the fact that if we show an extra income will that be helpful for us to obtain the visa or not.
3. For the time being my sponserer has come to my country.since last two months she was here.she is expecting to leave thecountry with us when we get our visas.Will it be o.k for her to be here during our visa interview? .Has she to show her return tickets on our visa interviews?
4. At the moment my husband is staying abroad.He works there.he is expecting to come to his mother land 20 daysbefore the visa interview.He will come for one months holiday,and if we get visa he hopes to go to his working place and get him self resign from his job .So that both of us will be able to go to USA together. As he is on leave, if we get the visas soon it wont be a problem,but if it gets delayed more than two weeks my husband wont be able to report to his work as he is not having his passport.If such a thing happens what is the steps that we have to follow?
5. Acording to my case no(48XX)I expect that my interview will be on March or April.CEAC site shows that I am “at NVC” status .I have to insert some detaills to my DS 260 application.For that I have to unlock that , as the interviews are on process will that unlocking DS 260 will affect my interview date? That is , I wanted to know will there be any delay in my interview?
« Older Comments
January 6, 2018 at 17:57
Are you from Nepal??
January 6, 2018 at 16:45
hello
there are full statues “ready” this status represents a status “issued” later ??
January 6, 2018 at 18:11
Not always. It means a case that is scheduled for interview.
January 6, 2018 at 17:58
With case number 2018Af29xxx from Cameroon am I at the risky position or should I expect a letter May?
January 6, 2018 at 18:08
Read my latest post.
January 7, 2018 at 22:46
Brit, in your chart for Europe, right after the 26601-26700 is going 27301-27400. What does it mean?? Where is 26729 case number??
January 8, 2018 at 03:49
The man who thinks he knows more than me can’t work that out???
Really. Have a look. Use some common sense.
January 8, 2018 at 15:17
Thanks for your kindly reply. You are very polite.
January 8, 2018 at 15:38
Hahaha. After your idiotic trolling, insults, and negativity you expect me to politely answer your questions now??? I don’t know why you are still here. Your number has no chance – that is what you said – right? And my info was just “empty opinions”! So – why are you still reading my blog or even thinking about DV?
January 8, 2018 at 07:05
I looked at the EU chart, and didnt understand it. Not all case numbers in it. Mine is 196XX. So whats the problem?
January 8, 2018 at 07:18
Sorry, mine is 199XX.
January 8, 2018 at 15:04
It’s a RANGE of numbers – only showing numbers every so often. Please read the article rather than just looking at the picture.
January 8, 2018 at 15:29
Hi Brits. Thanks for too much effort. you will lose you hairs. wish you best of luck. Regards,