
As most of you will know the CEAC system was recently modified in a way that means I cannot extract the data. This is a disappointment to me personally – but also to the many people that gain understanding and insight from seeing this data. I have emailed the Department of State to request access to the data but I don’t hold out a lot of hope. They may even remove the CAPTCHA functionality themselves but if they don’t we are in the dark about how many visas have been issued and so on.
I have detailed below the description of a possible solution. It will take some community spirit and assistance both to get this developed and then on an ongoing basis. If no one does any work, we will be in the dark. I am happy to help as I have the central platform that everyone can use to collaborate. I have been studying the DV program since 2013 – and I consider the CEAC data to be a critical aspect of the understanding we have of this process.
So the question is – can we do this together?
I would like to hear from programmers by email with an understanding and perhaps simple proof of concept, once the solution is agreed. The solution is a starting point – I would be happy to get input from experienced engineers if anyone feels there is a better way to do this.
Problem statement
The recent addition of a CAPTCHA challenge on the CEAC site has curtailed the use of the screen scraping script that was previously in use. We are looking to re-instate the ability to extract that data by pooling community freetime as a resource.
Solution – high level.
The proposal is to build a webpage (form) hosted at BritSimonSays.com where interested community members could solve CAPTCHAs and thereby facilitate the extraction of CEAC data.
The member would open the webpage and enter their Member ID (any name they want to use) and an email address. That information should be saved by a cookie to allow this to persist in the form.
The member then clicks a button to solve a CAPTCHA. Scraper code would open a session with the CEAC site and retrieve the image of the CAPTCHA to present in our form. The member keys in the CAPTCHA and the scraper code would submit the captcha along with a Case Number. If the solve is correct the scraper code would then log the resulting case details to a database table.
The form provide feedback for the solving of the captcha and would refresh the form so the member could solve another captcha.
Captchas take around 10 seconds to solve (less as people get more expert). The scraper would retrieve and log the case in around 1 second or less.
So – one member donating around 10 minutes of time would solve around 50 to 100 cases. We would need a few hundred people around the world doing that on a regular basis to keep the extracts up to date. Their efforts could be tracked and frequent solvers would earn community appreciation, respect and admiration (!) – perhaps encouraged by publishing league tables of the most frequent extractors. I might be able to get some giveaways or at the very least – easy access to me for my case advice and assistance.
CEAC data would be being extracted and constantly refreshed by user input. The data itself could be extracted and made available by shared spreadsheet (as I have in the past) or perhaps constantly available (on demand).
What would be needed to make all this happen
Obviously this solution would rely on the community to come together and have many individuals donate some of their time to get us the data we are all interested in seeing. In this case, the old saying of “many hands make light work” is especially true.
http://www.nsvrc.org/sites/default/files/styles/large/public/86510296.jpg?itok=8pOHzduH
The second aspect of what would be needed is some development help. My own IT skills are mainly in other types of enterprise systems, so although I know what sort of work needs to be done, I don’t have the technical skills to do this by myself. It is not that complicated – probably a few hours work for a good web developer. I already have a good understanding of what needs to be done, some code examples for how to implement the scraper. That would be based around the selenium driver with python or java.
The suggestion that this should be hosted on my site is because I already get sufficient traffic to enable this process. Via my site I have a significant readership which of course builds with each year due to the CEAC data itself but also the background information and assistance I provide. I currently pay for the hosting of my site myself, but I may decide to add some advertising to this page to fund the hosting costs associated with this increased functionality.
Technical detail and requirements (plus an indication of what code I have and where I would need development help)
The main piece of functionality is the page itself. I would imagine this would be an asp page or similar, capable of running the scraper code and interacting with a SQL database.
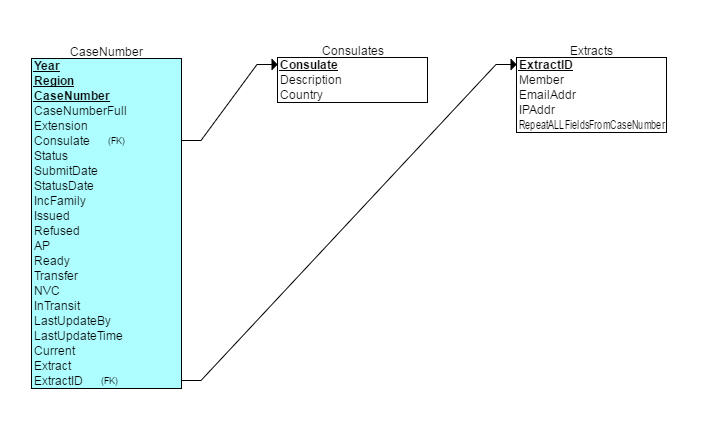
On my hosting website I have the ability to create a MySQL database and I have a database design (ERD below) that would support the solution.
I also have code that worked until recently (this is written in java), and have some experience of using selenium with python, although selenium works with java too. The reason to suggest using selenium is to be able to present the captcha image to be solved and at the same time passing the case number and retrieving the case details.
The form should allow multiple concurrent sessions using an algorithm to pick a case to extract once the user solves the captcha.
The form should be in some format that is deployable on my hosted website. I will maintain the complete source code for that page and all the functionality. In order to avoid having the Department of State move the goalposts again, it would be smart to not allow the scraper code to become publicly available.
A main table (CaseNumber) will store the extracted data. This will represent the latest status of each case. This is very similar to the format of the Excel spreadsheet I already produce. This is based on the data I know is available for each case, and will allow the presentation of the data to be very similar to the data people are used to seeing. There are five additional fields in that table:
- LastUpdatedBy – The member ID entered on the form for the extract/update that occurred last on that case.
- LastUpdatedTime – The time of the last update. As we move through the year (after the initial extract of ALL data), the system could select which case number to extract based on the oldest record. That way, we would be constantly directing the online effort to extracting the latest possible data.
- Current – is the case current or not according to the visa bulletin. This value (a Y/N boolean) will allow us to focus the extracts on current cases only.
- Extract – Should the record be extracted or not (a Y/N boolean). Again this allow us to turn on or off extracts for certain records. For example, once a case and all derivatives are marked as issued, there is no need to continually update that case. This, in conjunction with the current flag, and the last updated time will allow us to direct the online effort in the most efficient way.
- ExtractID – FK to the Extracts table.
Another table (Extracts) will store information about who extracted the data and take a snapshot of the update at that time (i.e. all the fields from CaseNumber table apart from the final 5 fields). By tracking the Member (and optionally getting an email address for the member) we can give some “credit” to the people doing the work. The table will also provide a history of status on each case over time. That history will allow us to better understand the time taken to resolve AP cases in particular, and see trends by consulate.
The Consulates table will allow us to provide a data mapping between the consulate ID provided in the CEAC file and the city/country assigned to that ID. We could therefore provide better searches of the consulates by country, or city. Furthermore I could extend this table in future to track certain data points, such as which consulates require an I-134, email or contact details for the consulates and so on.
It might be necessary to conceal the IP address in some way in order to make sure the activity is not seen as a robot. Because the volume will be based on human activity, this should not actually cause a problem for the DoS servers (and therefore should not illicit any action to foil our process.
I already have code snippets for selenium and working java code for the extract. I have the hosted website, I can create the database tables, and of course I have the global reach to the many hands that will make this possible!
Timeline for this proposal.
Well, that depends on the response and assistance I receive. I know this solution could be implemented. I am looking for a developer with appropriate skills to contact me (britsimon3 at gmail), so we could collaborate on this solution. If we work fast we can perhaps implement this in time to restore the access to CEAC data in a short timeframe for the remainder of DV2016. Since DV2016 is in progress, there are a great number of the 55000 cases that we can exclude from the extract (cases not current, cases already issued and so on). So – the extract could be fairly quick (I expect it could be done over a period of a few days).
Once DV2017 starts, CEAC data will not be available for a few months (CEAC is typically loaded around January 1 of each year). By that time, The DV2017 selectees will understand the value of the CEAC data and will hopefully take some responsibility to get the work done for the initial extract and incremental extracts thereafter.
However, I can’t do this all myself – does anyone want to help?

April 19, 2016 at 22:25
Hi Simon,
I am an old reader here; I subscribed to your blog that’s how I got here as I was alerted through email about this post..
This looks like a neat idea and you seem to be knowing what you are abut doing. I will be pretty glad to help you out with the develpement and data handling and processing etc..
In my opinion I think we’ll get and store all the captchas at a certain direcrtory and serve them to public in a table to save and update existing solutions, etc.. I can help you with that, you might just create a separate subdomain for the sake of this one and I am pretty sure the community will volunteer as long as you share about this in the Facebook groups and visajourney/immi forums …
But again, are you sure this is legal? I mean, to hit someone’s website repeatedly that will eat up some of their server ressources, but in the end, that is nothing for them..
I really have so many ideas for this one, even making status check calls and matching the captcha image with the ones solved then proceed the case.. We should test this out first..
I will wait for your reply.
Samuel
April 20, 2016 at 05:14
Hi Samuel. I honestly don’t have a concern about the legality. The load with the method I am suggesting is less that the full extracts I have been doing and I know others have been doing similar extracts more often than I have been doing. So – since they have the CAPTCHA in place they have ensured humans can access (and therefore record) the data. The copyright notice says the information is in the public domain. I’m not concerned.
I’d be interested in hearing more of your ideas. I don’t know how many unique captcha combinations there are – I’ll do some research. But for your idea, there needs to be an OCR solution to match the graphic to a previously solved graphic. If you have some ideas you want to demo – do a simple POC and we could take a look at it.
Thanks Samuel!
April 20, 2016 at 13:32
Good morning,
Well thanks for confirming so.
I am not experienced with Java, but I am pretty sure PHP and JavaScript can do this task entirely, besides SQL or NoSQL for the database part.
I have a little experience with Captchas, I login to a website frequently and each time I login (in Chrome), my captcha input gets to be saved and most of the times when I try to fill a captcha, chrome suggests me the correct solution which I have input before. This can mean that captchas are limited and it’s just that it takes some time to be served a Captcha image that you have solved already. So yes, people will answer so many captchas out there, and then we’ll do the matching when we make calls to get status info..
I will launch a script to get as many captcha images as possible and save them in my computer and avoid saving a captcha if it is already saved, so as to get unique images.. and once done, my thinking is to upload these and serve them to volunteers in order to solve them or update existing solutions if they were mistaken..
As for the OCR, I have found couple libraries over Github and I am going to try them out.. I will make few tests to make sure how this thing will be.
If this works, I will even try to get status check with JavaScript so you won’t have to worry about any other part, and get the data in a CSV file in the end of the task..
I am sending you an email as this discussion should continue privately. I am glad to see people are already interacting with this one 🙂
Thanks,
Samuel
April 20, 2016 at 05:03
Hi Simon, count me to capture the CAPTCHA (no pun intended) once you get web developers. I won’t let you down plus all the stakeholders in this priceless forum. TIA.
April 20, 2016 at 05:05
I am totally blind about the matter otherwise I would volunteer if someone instructs the procedure in detail.
April 20, 2016 at 05:44
If we can implement a solution it would be VERY simple to use.
April 20, 2016 at 06:48
Dear Simon,
I’m not a web developer but if any assistance needed you can count on me (like to capture the CAPTCHA).
Courage
April 20, 2016 at 08:56
I am pleased to help you by manually input known case number and write all information to Excel one by one . I think 500 case is about 4 to 5 days . I will do it as long as I have free time . We need to have people to join together . One person can gather data about 500 case so if we have like 200 people . We can gather 100000 case in our data . We assign people in group.group Asia region , group Africa region , Group Europe region , OC region . Why can’t we do all of this ? Of course we can . I am the one to be your help .thank for your service to everyone
April 20, 2016 at 12:59
The automated solution would make the task a lot easier. The humans solve the captcha, the system records the case information (in less than a second), and the human goes on to the next captcha. Also, the system picks the case numbers so the humans don’t have to communicate to agree who will capture which cases.
April 20, 2016 at 15:25
hi dear, mr simons greetings and my respect for you
I am a regular user of the computer, but I have many friends specialize in the field will help me and I will give you what we found
April 20, 2016 at 15:55
Hello,
I do not have a sponser in USA but I have like 12k dollars in the bank and a house as an asset under my name.
Im a single applicant.
Do you think this is enough?
April 20, 2016 at 18:31
In most embassies it would be.
April 20, 2016 at 16:53
HI brit
I am ready for any help I can do, I am a regular computer user but have enough free time to work on the captcha.
Just a thought : I noticed that the numbers of CN interviewed in order to fulfil the 50000 visas are about 110000 in 2015, 125000 in 2014, 120000 in 2013 and much higher in older DV. Now knowing that the total number of winners in DV 2016 is 91000 , is it possible that all regions will become current or hit a very high numbers this year ?
Because they still have to interview an average of 115000 to fulfil the available visas ( I think the people have not changed over this year !!)
Areen from Jordan
April 20, 2016 at 18:31
You are a bit confused about selectees versus case numbers. Each case number represents a winner and the family members, whereas the annual numbers you quote include family. . So, in DV2016 the 91k winners are on about 55000 unique case numbers.
The average number of winners that worked well was around 100k to 115k. DV2014 had 140K and many were left without an interview. DV2015 had 125K and still people were left without an interview. However, this year, they reduced the number of selectees greatly in EU and OC – and those regions are already current. AF and AS are still oversubscribed (particularly AS). So – AS will have a cutoff, AF will probably have a cutoff, and SA probably will also.
April 20, 2016 at 19:05
Aha I understand now , thank u 🙂
Just one more question : can we know what’s the highest case number for AS and AF for this yr ?
If yes please let me know them
Thank u
Areen
April 20, 2016 at 19:19
The highest numbers assigned are shown in the CEAC file.
If you mean what will be the highest numbers to be called for interview – we don’t know yet.
https://britsimonsays.com/april-1-ceac-update/
April 20, 2016 at 16:55
Count with my help! Maybe 10, 20 or even 30mins!
April 20, 2016 at 19:59
I’m here ..i’ll be here .. just tell me what to do and i’ll do it . you can rely on me .
April 20, 2016 at 20:59
HI BRIT
i know it is a bit late question , but is there any fees that i should pay after sending the ds-260 form ?
thank you
April 20, 2016 at 23:10
You will pay the $330 per person at the embassy on the day of the interview.
April 21, 2016 at 07:42
you can count on me our super moderator i will do my best to help you .
April 21, 2016 at 13:08
Hy Brit what happens if someone is diagnosed with TB during medical can it cause denial?any such case
April 21, 2016 at 21:23
Give me task of any 1000 case i can check individually and report to u
April 21, 2016 at 21:42
Thank you. That would be quite time consuming – so I am keen to develop a systematic way to do this that uses human effort such as you are kindly offering. Hopefully I will have some news on that….
April 22, 2016 at 00:49
Hy Brit what is the the impact of TB on green card can it cause denial
April 22, 2016 at 02:55
Did you check the FAQ?
April 22, 2016 at 08:25
Hi Brit. As you say the solution should be easy, I’ll be glad to help. By the end, we are helping ourselves
April 22, 2016 at 12:31
Will,do my best,though am not a computer specialist.A question for you sir.Do I need to send my DS 260 again if I already sent it once does it expire after some time?coz I sent it last year on July and my interview probably will be in September God willing .
April 22, 2016 at 14:21
It does not expire – you send it in once, but if you need to update it, you can do so by emailing KCC to unlock the form.
April 22, 2016 at 16:25
Hy brit plz give me your email
April 22, 2016 at 21:00
britsimon3 at gmail d o t com
April 22, 2016 at 18:17
Hi simon. I received my 2 nl letter. Asia 7200. First submission june 2015, unkock and resubmit by august 2015. Interview end of june. All the best for all. Thank you simon for ur help
April 22, 2016 at 19:16
Dear Brit ‘Namaste’ (good morning )I hope
People started getting 2NL for June interview If I’m not wrong. I got 2NL for June 6 interview, submitted on July 2015 and resubmitted on 24 January 2016. Thanks for all that you have been helping me and people all over the world.
April 22, 2016 at 19:24
MY dear Brit,
Namaste(good morning)
I got my 2NL for June 6 interview, submitted on July 2015 and resubmitted on 24 January 2016. Thank you very much for your help and good luck to everyone
April 22, 2016 at 21:22
Hi Brit
Thanks for all the many helps you have been given to all of us even though I’m not yet through but things seem to look good for now.
I just received my interview letter for the 16th of June 10 am Monrovia US Embassy.
Thanks for your tireless efforts on this blog
April 24, 2016 at 18:41
Hi Benjamin ,
Nice to hear that u have u interview in June. I wish u d all d best n most of all success. Wats ur case number pls
April 23, 2016 at 11:05
hello Brit. I know you are very busy now. can we wait for predictions this month or do we have to wait till solution is find to extract ceac data? For, you said you’ve a lot of information to continue to predict DV 2016. Thanks
April 23, 2016 at 15:54
Well in the past two months I have said what will happen in AF – so Africa is clear. AS region is getting to “unknown territory” because we are already above the max number reached last year. Given that – I may not have done a normal prediction anyway. I’ll write up something in the next few days.
April 24, 2016 at 12:24
Hae super moderater,I made a mistake when submitting my DS 260.what happened is that in 2010 I wanted to join Missouri university but on the appointment day at the embassy I found that my interview had been cancelled,I don’t know who did it whether it’s a member of the family so I could fail so I did not attended the interview,but some one told me that it may have been cancelled because my bank statement could not support me.So when submitting the DS 260 I said I had been denied a visa before due to financial problems.could such statements affect me on the appointment day and make me to be denied a visa or should I unlock the DS 260 and change?coz I did not meet the consular face to face I was informed by the assistant at the embassy then that my interview had been cancelled.
April 24, 2016 at 16:56
Don’t worry about it. The CO might ask you to explain. That’s all.
April 24, 2016 at 18:28
Thanks sir.God bless u
April 27, 2016 at 21:53
Dear brit, should be there any hope to reach the ceac data for the rest of 2016?
April 27, 2016 at 22:51
I don’t know yet.
May 2, 2016 at 13:49
Britsimon! What happened with this? O offer again my time helping solve some captchas. I’m ready!
May 2, 2016 at 13:50
Thank you – but the software is not ready.
May 31, 2016 at 16:00
Hi Mr. Simon, I hope you are ok, can you please help me with my question! I have done some training and obtained some certificates form my work places. Can I add them on my ds 260 ?
Thanks
May 31, 2016 at 16:54
If you would like to.
June 7, 2016 at 09:03
What’s up Brit, how many months did the yellow fever vaccination card is valid for?
Thanks
June 7, 2016 at 14:14
I don’t know.
June 20, 2016 at 23:55
hi brits is the software out in days or it’s gonne just be for the dv2017
June 21, 2016 at 00:02
I’m not working on it at this time
January 16, 2017 at 22:06
Hi Mr Simon
What are the updates about the software? im here to give help if you still working on it 🙂
January 17, 2017 at 04:08
No updates – I have not worked on it at all.